特洛伊代码
文章目录

ref link: Trojan Source
一篇关于“特洛伊代码”的读书笔记。
TL;DR
U+202E Right-to-Left Override(下文简称RLO)是一个老生常谈的特殊符号了。无论是上面的 xkcd 1137,还是之前很多人的微信昵称,都经常能看到。
文章“特洛伊代码”中介绍了一种潜在的代码攻击方案。主要是通过RLO和其他一些文本顺序描述字符的组合使用,让用户在代码编辑器里看到的代码和编译器理解的代码并不完全相同。
RLO 和 它的兄弟们
简而言之,RLO会让后续的文本按照从右到左的顺序去显示。这个显示效果会一直持续到接下来的一个换行符(或者是一些其他更复杂的规则,譬如 U+202C PDF)。
举个例子来说,下面这段“你好世界”:
|
|
其实是由“[RLO] 界 世 好 你 [PDF]”显示出来的。
同时在一个R-to-L的文本环境中,用户可以通过使用 U+2066 Left-to-Right Isolation来引入一个局部的L-to-R的文本环境,并通过 U+2069 Pop Directional Isolate来取消之前的RLI。例如下面这段“你好世界”:
|
|
是通过“[RLO] [LRI] 世界 [PDI] [LRI] 你好 [PDI] [PDF]”构造而成。
在最外层的R-to-L的环境里,又构造了两个L-to-R的文本环境,让逆序文本的构造更为简单轻松。
更多的关于文本顺序的规则,参考 Unicode TR 9。反正我没看。
攻击方案
尽管我们可以在文本中通过插入RLO和LRI的组合,让文本的内存顺序和显示顺序完全没有关系。 但是在主流编译器的眼中,代码是强格式约束的,这些特殊字符并不能出现在任意的位置上。
而“特洛伊代码”的作者还是找到了两个可以塞任意符号的位置:字符串,注释。
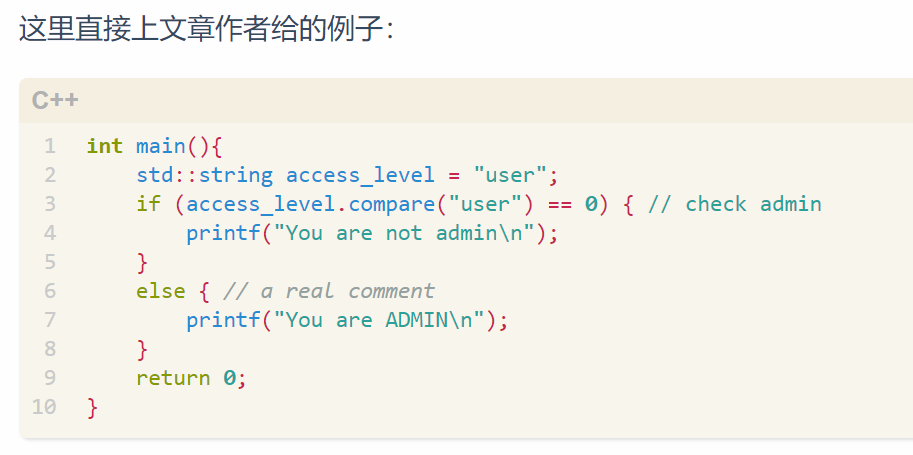
这里直接上文章作者给的例子:
|
|
一眼看上去,这里是应该输出“You are not admin”的。而实际的输出结果却是“You are ADMIN”。
其中具体的原因就是if那一行的代码其实是
|
|
这里省略了不必要的 [PDF]。
应对方案
“特洛伊代码”的作者从两个角度讨论了如何避免类似的“特洛伊代码”攻击:使用代码的编译器和显示代码的编辑器。
编译器
从编译器的层面来说,很显然最简单的方案就是禁用这些字符。
或者至少在遇到这些特殊字符的时候,给出一个合适的warning或者error。就像最新版的 rust 会做的那样:
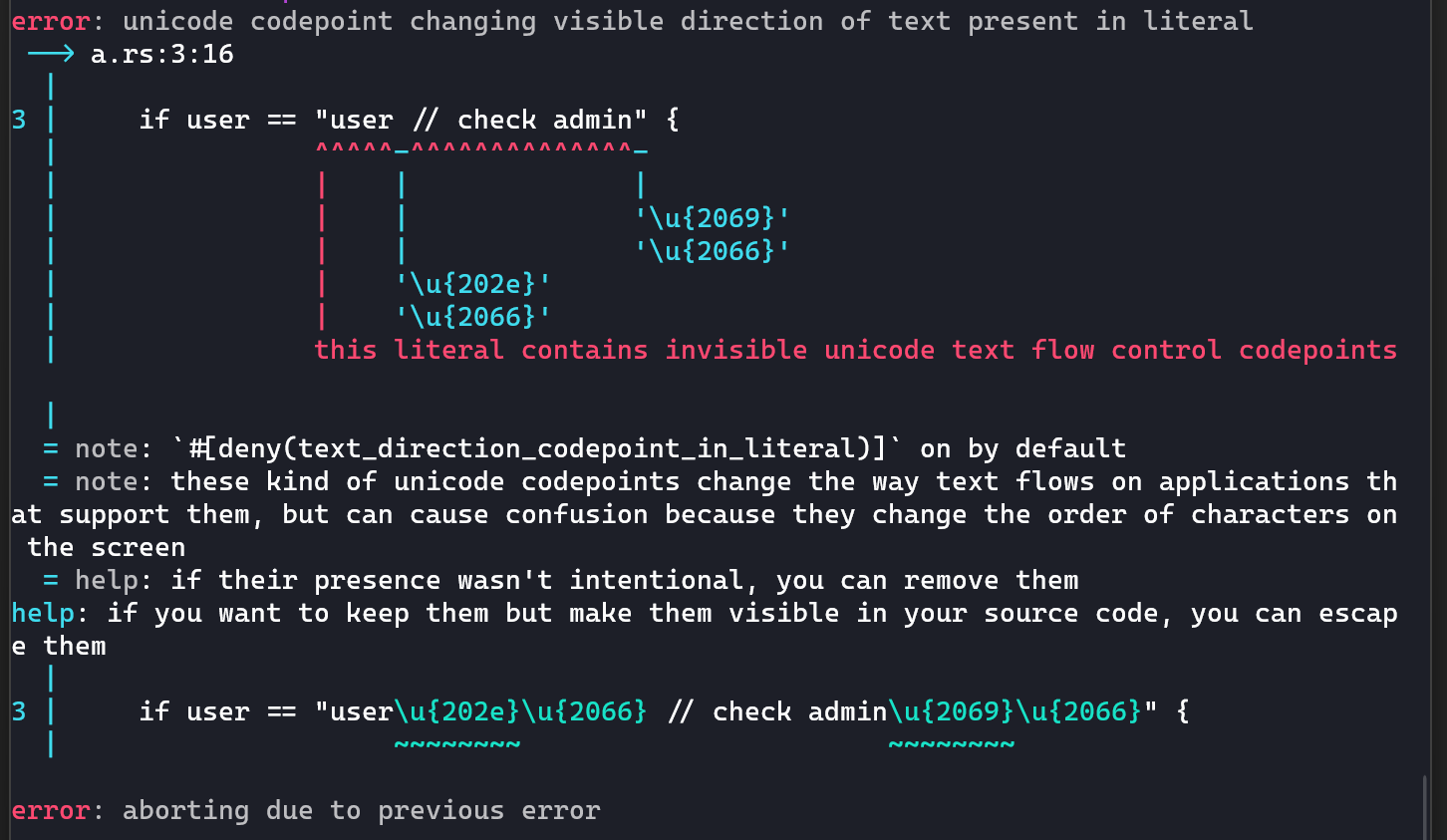
而在真正需要这些控制符号的时候,就像上面的错误信息一样,完全可以可以通过类似 escape character 的方式来避免在代码中直接出现 U+202E。
|
|
编辑器
对于编辑器来说,更合适的方案则是用特殊的方式来显示这些特殊的字符。
就像我在写这篇读书笔记的时候,VS Code 会把 U+202E 直接显示成 [U+202E]:

在原文作者写那篇文章的时候,包括VSC在内的大部分编辑器,无论是本地的还是网页的,大都没有对这些特殊字符做特殊的处理。VIM 是其中位数不多的例外。不过我觉得是VIM无法正确的显示它们。
相比之下,基于 Web UI 的代码阅读似乎就没有那么优秀了。(虽然说VSC四舍五入也是一个Chrome)。在我写这篇读书笔记的时候,Github 依然会按照标准的文本渲染模型去显示包含 RLO 的代码。
这里的这样问题是,很多时候我们(至少我是这样)在review别人的代码的时候,经常是在在网页里看看就直接点了。
就像原文作者提到的那样,也许我们可以祈祷 语法高亮 程序能够帮助我们,让这些特洛伊代码无处藏身。但是事实上,实际情况并没有想象中的那么美好。就像我在预览这篇文章的样例的时候,我看到的恶意代码差不多长这样:
如果不是我在截图的时候特意加上另一个真正的注释,单纯看上面的部分,我相信很多人无法第一时间意识到情况的异常。
依赖工具的检查,而不人的细心。
其他特殊符号
在 Unicode 中,除了文本书写方向的控制字符,还有两类有趣的符号:
- 不可见字符
- 相似字符
不可见字符
除了emoji中常用的ZWJ以外,还有一些排版时候会用到的0宽度空格,例如 U+200B Zero Width Space 或者 U+2060 Word Joiner。
分享一个我所在的团队之前遇到过的一个问题。背景是我们有一组REST API,对应的swagger和swagger生成的各种语言的客户端。一切都挺好的。直到有一天,我们遇到了一个奇怪的现象,某一个API用客户端可以访问,但是自己用postman去调试就一直404。后来发现我们的URL里包含了一个不可见空格。事后我们怀疑是从网上抄代码,复制粘贴的时候带进来的。同事当时还问我是怎么发现这个问题的,我只好说“我能看见常人看不到的东西,就像你背上的那个小人”。
相似字符
分享一个我特别喜欢的 Stackoverflow 上的一个问答:Can (a== 1 && a ==2 && a==3) ever evaluate to true?。简而言之,有很多长得像 a 的符号。
之前也有过攻击者用这些相似的符号去构造钓鱼网站的域名,譬如说 http://pаypal.com。如果你复制这个网址到浏览器里的,主流的浏览器已经够会把它显示成 http://www.xn--pypal-4ve.com 了。
攻击利用
“特洛伊代码”的作者也讨论了这两种类型符号的攻击利用,但是总的来说是没有发现什么特别有用的攻击角度。
在这里我倒是有个非常不一样的观点。最近体验了包括 Copilot 在内的若干个基于AI和GPT的代码补全工具。
平常我写5分钟的代码,AI差不多不到1秒就能帮我 正确 地全部写完。我之前写了个一个BFS,50行上下得代码,大概只有10行不到是我自己写的。而问题是,在AI写完以后,我由于过于震惊,还花了差不多10分钟得时间去review它的代码。
在意识到AI写的确实好以后,我花了大概30分钟的时间,才从 震惊 和 恐慌 的情绪中平复下来。
可以说是 非常耽误 工作效率了。
这里主要是想说,一旦开发者(这里指我)习惯于让AI去写那些重复性的简单代码的话,而AI在生成的代码里,恰好又插入了这些肉眼无法识别,或者难以区分,的符号,那么开发者(还是指我)将几乎不可能识别出这些问题。而超大AI模型的训练经验告诉我,想要在训练数据里插入恶意输入,实在是太容易了。
这并非危言耸听,回想一下几年前,微软的聊天机器人Tay是怎样从一个无知少女,在一天之内就变成了一个可怕的,支持纳粹的,互联网巨魔。
着实希望之前提到过的编辑器和编译器团队,能够像对待 RLO 一样对待这些不可见字符和相似字符。
如果有人因为看了这篇文章,发了相关的CVE,记得告诉我一声。
钱
“特洛伊代码”的作者在文中同样提到,通过做白帽卖CVE,挣了一万多刀。
真好啊,真好啊…………
外链汇总
- Trojan Source: https://trojansource.codes/
- XKCD 1137: https://xkcd.com/1137/
- Unicode Bidirectional Algorithm: https://www.unicode.org/reports/tr9/
- Unicode Security Considerations: https://www.unicode.org/reports/tr36/ and https://www.unicode.org/Public/security/latest/confusablesSummary.txt
- Whitespace in Unicode: https://en.wikipedia.org/wiki/Whitespace_character#Unicode
- Can (a== 1 && a ==2 && a==3) ever evaluate to true?: https://stackoverflow.com/questions/48270127/can-a-1-a-2-a-3-ever-evaluate-to-true
- ZWJ in emoji: https://blog.emojipedia.org/emoji-zwj-sequences-three-letters-many-possibilities/
文章作者 srayuws
上次更新 2021-12-06